
ceph-纠删池 osd两次隐射
ceph 集群数据落盘
hash 取余,存放于对应的hash环节点上
以节点为hash 环,节点down 机造成大量数据迁移。
不以物理节点为余,采用逻辑结构,池,,
数据分布规则 副本规则,crush 规则,池中为多个pg 组成 pg,也是一个逻辑节点。把pg 为逻辑节点。
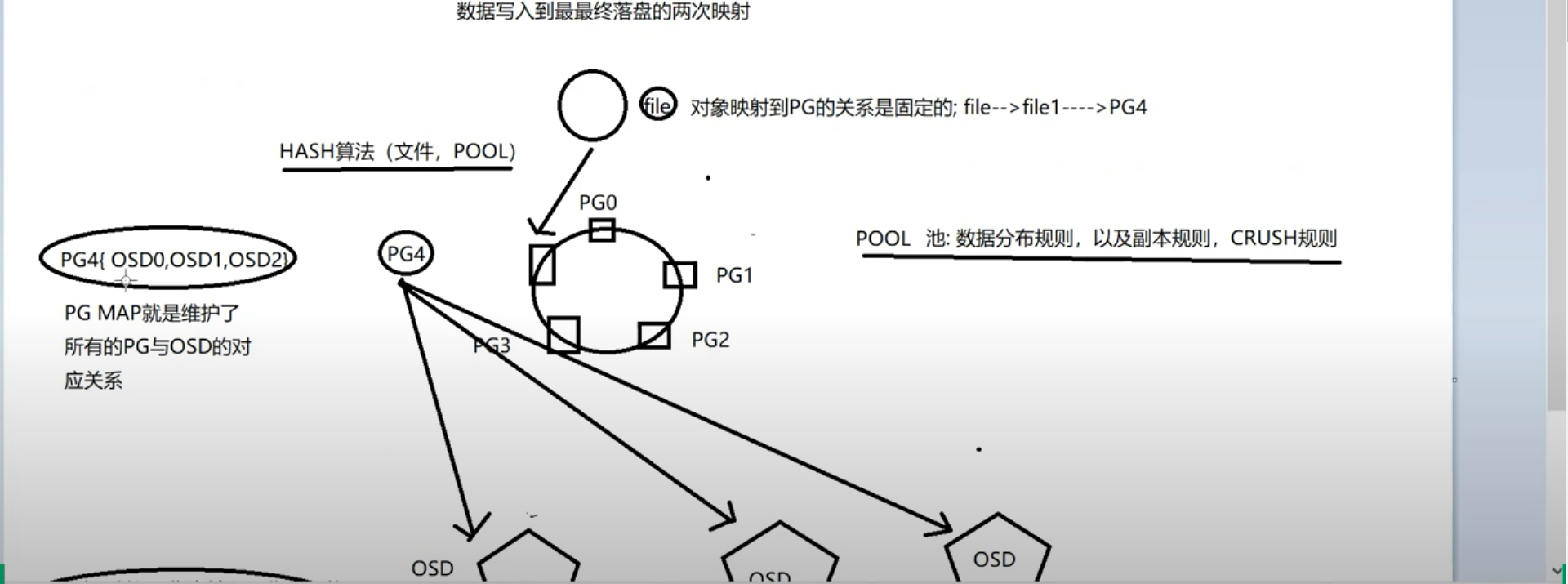
文件隐射到pg 中,
pg数量在pool创建时已经定义。。所以不会因物理节点变化而变化,使其做为hash 环,所以对象隐射到pg 的关系是固定的。逻辑架构pg,并不会存放数据,隐射到osd 中,定义池中的规则来确定。pg集合中定义了几个osd。
PG4(OSD1,OSD2,OSD3)副本规则,三副本规则。
crush 规则,二次隐射,以pg 做为输入,集群拓扑做为输出,,例: 硬盘在那个机架那台机器,为集群拓扑,,,因为要把数据存放至不同的地方,分散,为了安全嘛,大致意思就是这样。就是打乱了,存放于不同的地方。。最终得到pg----》osd 的隐射,在pool 创建时已经定义,
pg map ,维护了所有pg 和osd 的对应关系。
例:对象写入时。 hash 算法以pool和对象做为输入,定义某个pg 根据pg map找到osd 找到主osd。 客户端从主osd 通信, 主osd下发写入从osd 返回ACK。
(创建池已经映射好了)osd 和pg 的映射
两次映射。
指客户端—>hash 到pg
pg cursh---->osd
复制池(类似raid1):通过副本保证
纠删池(类似raid5):使用纠删代码,保护数据EC。就是把数据切片,冗余数据和纠删编码存放不同位置,丢失一部分数据,通过纠删码算法得到丢失的数据。。raid5 理解就理解了。 (4个数据块和2个编码块就需要6个osd,)想一下,分布至多个节点,还可以通过纠删码算回来数据,是不是达到了保护数据的目的。
纠删池:
默认配置集:
[ceph@serverb ~]$ ceph osd erasure-code-profile get default
k=2 数据块
m=2 编码块
plugin=jerasure
technique=reed_sol_van
[ceph@serverb ~]$
默认故障转移域为hosts, 例上面的数据块和编码块为2,需要四台主机,使用纠删池时,假如四台host其中一台出问题,,就删池数据就有问题了。
故障转移域可以设置为osd.
创建一个以osd故障转移域的配置集,emporer 以osd 为故障转移的配置集。
[ceph@serverb ~]$ ceph osd erasure-code-profile set emporer k=3 m=2 crush-failure-domain=osd
[ceph@serverb ~]$ ceph osd erasure-code-profile get emporer
crush-device-class=
crush-failure-domain=osd
crush-root=default
jerasure-per-chunk-alignment=false
k=3
m=2
plugin=jerasure
technique=reed_sol_van
w=8
创建纠删池:
ceph osd pool create < pool-name > 32 32 erasure(纠删池) emporer (配置集)
[ceph@serverb ~]$ ceph osd pool create emporer-erasure 32 32 erasure emporer
pool 'emporer-erasure' created
[ceph@serverb ~]$ ceph osd pool ls
device_health_metrics
cephfs_data
cephfs_metadata
emporer-erasure
查看池 ceph osd pool ls detail
ceph osd pool stats < pool name>
[ceph@serverb ~]$ ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 56 flags hashpspool stripe_width 0 pg_num_min 1 application mgr_devicehealth
pool 2 'cephfs_data' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 42 flags hashpspool stripe_width 0 application cephfs
pool 3 'cephfs_metadata' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 42 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfs
pool 4 'emporer-erasure' erasure profile emporer size 5 min_size 4 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 70 flags hashpspool stripe_width 12288
[ceph@serverb ~]$ ceph osd pool stats emporer-erasure
pool emporer-erasure id 4
nothing is going on
应用类型:
[ceph@serverb ~]$ ceph osd pool application enable emporer-erasure rbd
enabled application 'rbd' on pool 'emporer-erasure'
[ceph@serverb ~]$ ceph osd pool stats emporer-erasure
pool emporer-erasure id 4
nothing is going on
[ceph@serverb ~]$ ceph osd pool ls detail
pool 1 'device_health_metrics' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 56 flags hashpspool stripe_width 0 pg_num_min 1 application mgr_devicehealth
pool 2 'cephfs_data' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 42 flags hashpspool stripe_width 0 application cephfs
pool 3 'cephfs_metadata' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 42 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfs
pool 4 'emporer-erasure' erasure profile emporer size 5 min_size 4 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 71 flags hashpspool stripe_width 12288 application rbd
[ceph@serverb ~]$
纠删池写速度较慢,读还行,
复制池读写速度优于纠删,缺点占用空间,,n 个副本 利用率1/n.
和副本池操作一样。不一样就是有一个纠删集的故障转移域概念